When most data scientists start working, they are equipped with all the neat math concepts they learned from school textbooks.
However, pretty soon, they realize that the majority of data science work involves getting data into the format needed for the model to use. Even beyond that, the model being developed is part of an application for the end-user.
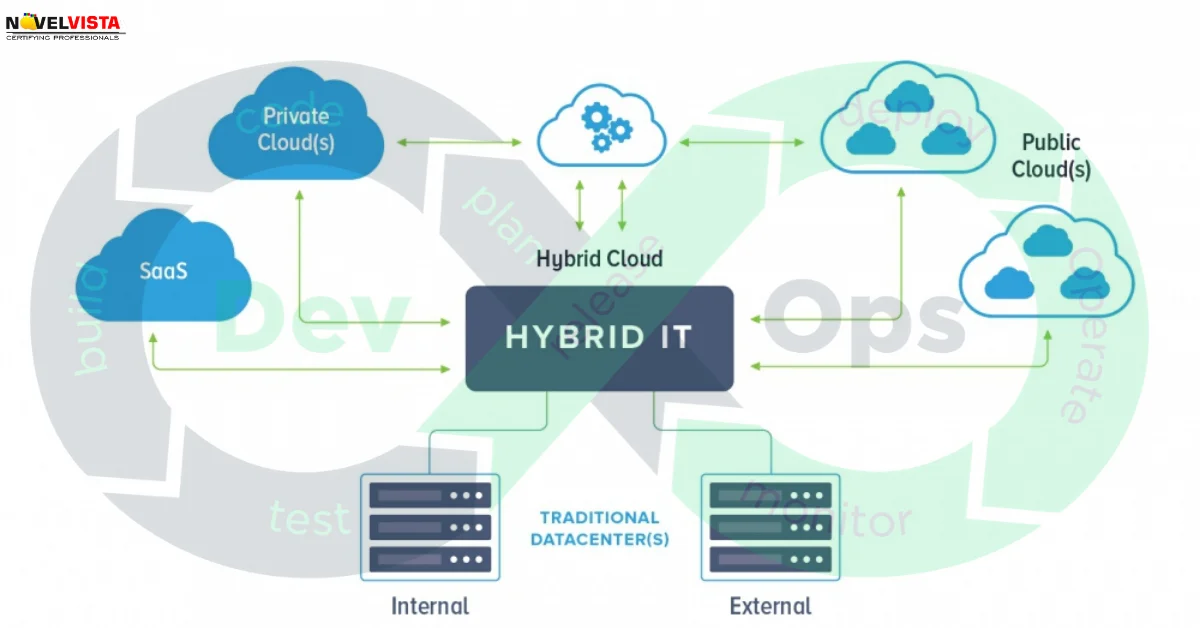
Now a proper thing a data scientist would do is have their model codes version controlled on Git. VSTS would then download the codes from Git. VSTS would then be wrapped in a Docker Image, which would then be put on a Docker container registry. Once on the registry, it would be orchestrated using Kubernetes.
Now, say all that to the average data scientist and his mind will completely shut down. Most data scientists know how to provide a static report or CSV file with predictions.
How will people interact with our website based on the outcome? How will it scale!? All this would involve confidence testing, checking if nothing is below a set threshold, sign off from different parties and orchestration between different cloud servers (with all its ugly firewall rules). This is where some basic DevOps knowledge would come in handy.
Long story short, DevOps are the people who help the developers (e.g. data scientists) and IT work together.
Developers have their own chain of command (i.e. project managers) who want to get features out for their products as soon as possible. For data scientists, this would mean changing model structure and variables. They couldn’t care less what happens to the machinery. Smoke coming out of a data center? As long as they get their data to finish the end product, they couldn’t care less.
On the other end of the spectrum is IT. Their job is to ensure that all the servers, networks and pretty firewall rules are maintained. Cybersecurity is also a huge concern for them. They couldn’t care less about the company’s clients, as long as the machines are working perfectly. DevOps is the middleman between developers and IT. Some common DevOps functionalities involve:
The rest of the blog will explain the entire Continuous Integration and Deployment processin detail (or atleast what is relevant to a Data Scientist). An important note before reading the rest of the blog. Understand the business problem and do not get married to the tools.
The tools mentioned in the blog will change, but the underlying problem will remain roughly the same (for the foreseeable future at least).
Imagine pushing your code to production. And it works! Perfect. No complaints. Time goes on and you keep adding new features and keep developing it. However, one of these features introduces a bug to your code that badly messes up your production application. You were hoping one of your many unit tests may have caught it.
However, just because something passed all your tests doesn’t mean it’s bug-free. It just means it passed all the tests currently written. Since it’s a production-level code, you do not have time to debug. Time is money and you have angry clients.
Wouldn’t it all be simple to revert back to a point when your code worked???
That’s where version control comes in. In Agile style code development, the product keeps developing in bits and pieces over an indefinite time period. For such applications, some form of version control would be really useful.
Personally I likeGitbutSVNusers still exist. Git works on all forms of platforms likeGitHub,GitLab, andBitBucket(each with its own unique set of pros and cons).
If you are already familiar with Git, consider taking a more Advanced Git Tutorial On Atlassian. An advanced feature I recommend looking up is Git Submodules, where you can store specific commit hashes of multiple independent Git repositories to ensure that you have access to a single set of stable dependencies.
It is also important to have a README.MD, outlining the details of the repository as well as packaging(e.g. using setup.py for Python) when necessary. If you are storing binary files, consider looking intoGit LFS(though I recommend avoiding this if possible).
A data science specific problem with version control is the use of Jupiter/Zeppelin notebooks.
Data scientists absolutely LOVE notebooks. However, if you store your codes on a notebook template and try to change the code in version control, you will be left with insane HTML junk when performing diff and merge.
You can either completely abandon the use of notebooks in version control (and simply import the math functions from the version-controlled libraries) or you can use existing tools likenbdime.
From a data scientist’s perspective, testing usually fall into one of two camps. You have the usual unit testing which checks if the code is working properly or if the code does what you want it to do. The other one, being more specific to the domain of data science,
Is data quality checks and model performance. Does your model produce for you an accurate score?
Now, I am sure many of you are wondering why that’s an issue. You have already done the classification score and ROC curves and the model is satisfactory enough for deployment.
Well, lot’s of issues. The primary issue is that the library versions of the development environment may be completely different from production. This would mean different implementation, approximations, and hence, different model outputs.
Another classic example is the use of different languages for development and production.
Let’s imagine this scenario. You, the noble data scientist, wish to write a model in R, Python, Matlab, or one of the many new languages whose white paper just came out last week (and may not be well tested).
You take your model to the production team. The production team looks at you skeptically, laughs for 5 seconds, only to realize that you are being serious. Scoff they shall. The production code is written in Java.
This means re-writing the entire model code to Java for production. This, again, would mean a completely different input format and model output. Hence why automated testing is required.
Unit tests are very common.JUnitis available for Java users and theunnittestlibrary for Python developers. However, it is possible for someone to forget to properly run the unit tests on the team before pushing codes into production.
While you can usecrontabto run automated tests, I would recommend using something more professional likeTravis CI,CircleCIorJenkins.
Jenkins allow you to schedule tests, cherry-pick specific branches from a version control repository, get emailed if something breaks, and even spin Docker container images if you wish to sandbox your tests.
Containerization based sand-boxing will be explained in more detail in the next section.
Sand-boxing is an essential part of coding. This might involve having different environments for various applications.
It could simply be replicating the production environment into development. It could even mean having multiple production environments with different software versions in order to cater a much larger costumer base.If the best you have in mind is using a VM withVirtual Box, I am sure you have noticed that you either need to use the exact same VM for multiple rounds of tests (terrible DevOps hygiene) or re-create a clean VM for every test (which may take close to an hour, depending on your needs).
A simpler alternative is using a container instead of a full on VM. A container is simply a unix process or thread that looks, smells and feels like a VM. The advantage is that it is low powered and less memory intensive (meaning you can spin it up or take it down at will… within minutes). Popular containerization technologies includeDocker(if you wish to use just 1 container)orKubernetes(if you fancy orchestrating multiple containers for a multi-server workflow).
Containerization technologies help, not only with tests, but also scalability. This is especially true when you need to think about multiple users using your model-based application. This may either be true in terms of training or prediction.
Security is important but often underestimated in the field of data science. Some of the data used for model training and prediction involves sensitive data such as credit card information or healthcare data.
Several compliance policies such as GDPR and HIPAA needs to be addressed when dealing with such data. It is not only the client that needs security. Trade secret model structure and variables, when deployed them on client servers, require a certain level of encryption.
This is often solved by deploying the model in encrypted executables (e.g. JAR files) or by encrypting model variables before storing them on the client database (although, please DO NOT write your own encryption unless you absolutely know what you are doing…).
Also, it would be wise to build models on a tenant-by-tenant basis in order to avoid accidental transfer learning that might cause information leaks from one company to another. In the case of enterprise search, it would be possible for data scientists to build models using all the data available and, based on permission settings, filter out the results a specific user is not authorized to see.
While the approach may seem sound, part of the information available in the data used to train the model is actually learned by the algorithm and transferred to the model. So, either way, that makes it possible for the user to infer the content of the forbidden pages.
There is no such thing as perfect security. However, it needs to be good enough (the definition of which depends on the product itself).
When working with DevOps or IT, as a data scientist, it is important to be upfront about requirements and expectations. This may include programming languages, package versions, or frameworks.
Last but not the least, it is also important to show respect to one another. After all, both DevOps and Data Scientists have incredibly hard challenges to solve. DevOps do not know much about data science and Data Scientists are not experts in DevOps and IT.
Hence, communication is key to a successful business outcome.
So if you are working in Data science or DevOps then you must learn both skills to be stand out from others then you dont leave this hanging enroll yourself for this courses likeDevOps FoundationandData Science Professional

Confused about our certifications?
Let Our Advisor Guide You